4. Writing Structured Programs (Extras)
This chapter introduces concepts in algorithms, data structures, program design, and applied Python programming. It also contains review of the basic mathematical notions of set, relation, and function, and illustrates them in terms of Python data structures. It contains many working program fragments that you should try yourself.
1 The Practice of Software Development
http://www.jwz.org/doc/worse-is-better.html
http://c2.com/cgi/wiki?DontRepeatYourself
import this
- Pages on Python pitfalls.
2 Abstract Data Types
2.1 Stacks and Queues
Lists are a versatile data type. We can use lists to implement so-called abstract data types such as stacks and queues. A stack is a container that has a last-in-first-out (or LIFO) policy for adding and removing items (see 2.1).
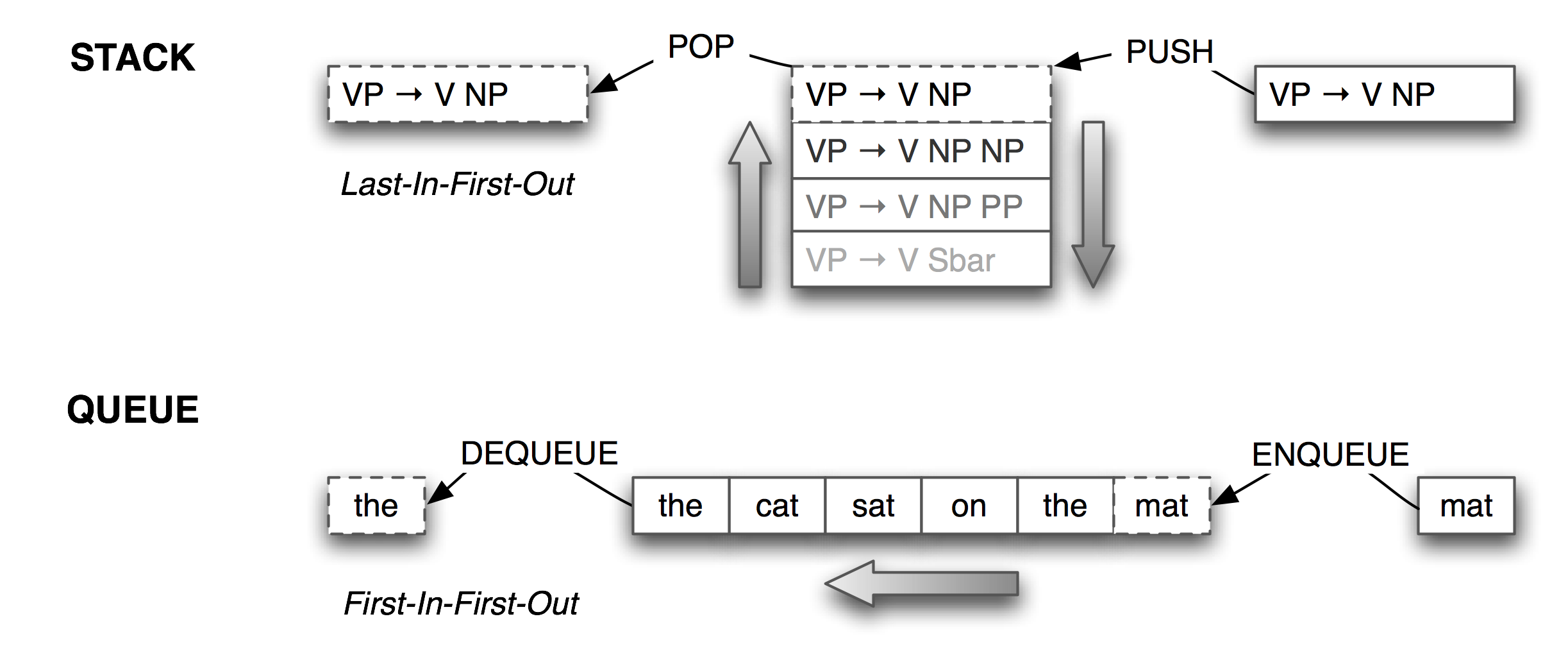
Figure 2.1: Stacks and Queues
Stacks are used to keep track of the current context in computer processing of natural languages (and programming languages too). We will seldom have to deal with stacks explicitly, as the implementation of NLTK parsers, treebank corpus readers, (and even Python functions), all use stacks behind the scenes. However, it is important to understand what stacks are and how they work.
| ||
| ||
Example 2.2 (code_check_parens.py): Figure 2.2: Check whether parentheses are balanced |
In Python, we can treat a list as a stack by limiting ourselves to the three operations defined on stacks: append(item) (to push item onto the stack), pop() to pop the item off the top of the stack, and [-1] to access the item on the top of the stack. The program in 2.2 processes a sentence with phrase markers, and checks that the parentheses are balanced. The loop pushes material onto the stack when it gets an open parenthesis, and pops the stack when it gets a close parenthesis. We see that two are left on the stack at the end; i.e. the parentheses are not balanced.
Although the program in 2.2 is a useful illustration of stacks, it is overkill because we could have done a direct count: phrase.count('(') == phrase.count(')'). However, we can use stacks for more sophisticated processing of strings containing nested structure, as shown in 2.3. Here we build a (potentially deeply-nested) list of lists. Whenever a token other than a parenthesis is encountered, we add it to a list at the appropriate level of nesting. The stack keeps track of this level of nesting, exploiting the fact that the item at the top of the stack is actually shared with a more deeply nested item. (Hint: add diagnostic print statements to the function to help you see what it is doing.)
| ||
| ||
Example 2.3 (code_convert_parens.py): Figure 2.3: Convert a nested phrase into a nested list using a stack |
Lists can be used to represent another important data structure. A queue is a container that has a first-in-first-out (or FIFO) policy for adding and removing items (see 2.1). We could use a queue of length n to create all the n-grams of a text. As with stacks, we will seldom have to deal with queues explicitly, as the implementation of NLTK n-gram taggers (5) and chart parsers use queues behind the scenes. Here's how queues can be implemented using lists.
|
Note
The list-based implementation of queues is inefficient for large queues. In such cases, it is better to use Python's built-in support for "double-ended queues", collections.deque.
3 Chinese and XML
Codecs for processing Chinese text have been incorporated into Python (since version 2.4).
|
With appropriate support on your terminal, the escaped text string inside the <SENT> element above will be rendered as the following string of ideographs: 甚至猫以人贵.
We can also read in the contents of an XML file using the etree package (at least, if the file is encoded as UTF-8 — as of writing, there seems to be a problem reading GB2312-encoded files in etree).
|
4 More on Defensive Programming
4.1 The Return Statement
Another aspect of defensive programming concerns the return statement of a function.
In order to be confident that all execution paths through a function lead to a
return statement, it is best to have a single return statement at the end of
the function definition.
This approach has a further benefit: it makes it more likely that the
function will only return a single type.
Thus, the following version of our tag() function is safer.
First we assign a default value ![[1]](callouts/callout1.gif) , then in certain
cases
, then in certain
cases ![[2]](callouts/callout2.gif) we replace it with a different value
we replace it with a different value ![[3]](callouts/callout3.gif) .
All paths through the function body end at the single return statement
.
All paths through the function body end at the single return statement ![[4]](callouts/callout4.gif) .
.
|
A return statement can be used to pass multiple values back to the calling program, by packing them into a tuple. Here we define a function that returns a tuple consisting of the average word length of a sentence, and the inventory of letters used in the sentence. It would have been clearer to write two separate functions.
|
[write version with two separate functions]
5 Algorithm Design
An algorithm is a "recipe" for solving a problem. For example, to multiply 16 by 12 we might use any of the following methods:
- Add 16 to itself 12 times over
- Perform "long multiplication", starting with the least-significant digits of both numbers
- Look up a multiplication table
- Repeatedly halve the first number and double the second, 16*12 = 8*24 = 4*48 = 2*96 = 192
- Do 10*12 to get 120, then add 6*12
- Rewrite 16*12 as (x+2)(x-2), remember that 14*14=196, and add (+2)(-2) = -4
Each of these methods is a different algorithm, and requires different amounts of computation time and different amounts of intermediate information to store. A similar situation holds for many other superficially simple tasks, such as sorting a list of words.
5.1 Sorting Algorithms
Now, as we saw above, Python provides a built-in function sort() that performs this task efficiently. However, NLTK also provides several algorithms for sorting lists, to illustrate the variety of possible methods. To illustrate the difference in efficiency, we will create a list of 1000 numbers, randomize the list, then sort it, counting the number of list manipulations required.
|
Now we can try a simple sort method called bubble sort, that scans through the list many times, exchanging adjacent items if they are out of order. It sorts the list a in-place, and returns the number of times it modified the list:
|
We can try the same task using various sorting algorithms. Evidently merge sort is much better than bubble sort, and quicksort is better still.
|
Readers are encouraged to look at nltk.misc.sort to see how these different methods work. The collection of NLTK modules exemplify a variety of algorithm design techniques, including brute-force, divide-and-conquer, dynamic programming, and greedy search. Readers who would like a systematic introduction to algorithm design should consult the resources mentioned at the end of this tutorial.
5.2 Decorate-Sort-Undecorate
In 4 we saw how to sort a list of items according to some property of the list.
|
This is inefficient when the list of items gets long, as we compute len() twice for every comparison (about 2nlog(n) times). The following is more efficient:
|
This technique is called decorate-sort-undecorate. We can compare its performance by timing how long it takes to execute it a million times.
|
MORE: consider what happens as the lists get longer...
Another example: sorting dates of the form "1 Jan 1970"
|
The comparison function says that we compare two times of the form ('Mar', '2004') by reversing the order of the month and year, and converting the month into a number to get ('2004', '3'), then using Python's built-in cmp function to compare them.
Now do this using decorate-sort-undecorate, for large data size
Time comparison
5.3 Brute Force
Wordfinder Puzzle
Here we will generate a grid of letters, containing words found in the dictionary. First we remove any duplicates and disregard the order in which the lexemes appeared in the dictionary. We do this by converting it to a set, then back to a list. Then we select the first 200 words, and then only keep those words having a reasonable length.
|
Now we generate the wordfinder grid, and print it out.
|
Finally we generate the words which need to be found.
|
5.4 Problem Transformation (aka Transform-and-Conquer)
Find words which, when reversed, make legal words. Extremely wasteful brute force solution:
|
More efficient:
|
Observe that this output contains redundant information; each word and its reverse is included. How could we remove this redundancy?
Presorting, sets:
Find words which have at least (or exactly) one instance of all vowels. Instead of writing extremely complex regular expressions, some simple preprocessing does the trick:
|
5.5 Space-Time Tradeoffs
Indexing
Fuzzy Spelling
6 Exercises
- ◑ Consider again the problem of hyphenation across line-breaks.
Suppose that you have successfully written a tokenizer that
returns a list of strings, where some strings may contain
a hyphen followed by a newline character, e.g. long-\nterm.
Write a function that iterates over the tokens in a list,
removing the newline character from each, in each of the following
ways:
- Use doubly-nested for loops. The outer loop will iterate over each token in the list, while the inner loop will iterate over each character of a string.
- Replace the inner loop with a call to re.sub()
- Finally, replace the outer loop with call to the map() function, to apply this substitution to each token.
- Discuss the clarity (or otherwise) of each of these approaches.
7 Search
Many NLP tasks can be construed as search problems. For example, the task of a parser is to identify one or more parse trees for a given sentence. As we saw in Part II, there are several algorithms for parsing. A recursive descent parser performs backtracking search, applying grammar productions in turn until a match with the next input word is found, and backtracking when there is no match. As we will see in 6, the space of possible parse trees is very large; a parser can be thought of as providing a relatively efficient way to find the right solution(s) within a very large space of candidates.
As another example of search, suppose we want to find the most complex sentence in a text corpus. Before we can begin we have to be explicit about how the complexity of a sentence is to be measured: word count, verb count, character count, parse-tree depth, etc. In the context of learning this is known as the objective function, the property of candidate solutions we want to optimize.
7.1 Exhaustive Search
- brute-force approach
- enumerate search space, evaluate at each point
- this example: search space size is 255 = 36,028,797,018,963,968
For a computer that can do 100,000 evaluations per second, this would take over 10,000 years!
Backtracking search -- saw this in the recursive descent parser.
7.2 Hill-Climbing Search
Starting from a given location in the search space, evaluate nearby locations and move to a new location only if it is an improvement on the current location.
| ||
| ||
Example 7.1 (code_hill_climb.py): Figure 7.1: Hill-Climbing Search |
8 Object-Oriented Programming in Python (DRAFT)
Object-Oriented Programming is a programming paradigm in which complex structures and processes are decomposed into classes, each encapsulating a single data type and the legal operations on that type. In this section we show you how to create simple data classes and processing classes by example. For a systematic introduction to Object-Oriented design, please consult the large literature of books on this topic.
8.1 Data Classes: Trees in NLTK
An important data type in language processing is the syntactic tree. Here we will review the parts of the NLTK code that defines the Tree class.
The first line of a class definition is the class keyword followed by the class name, in this case Tree. This class is derived from Python's built-in list class, permitting us to use standard list operations to access the children of a tree node.
|
Next we define the initializer __init__(); Python knows to call this function when you ask for a new tree object by writing t = Tree(node, children). The constructor's first argument is special, and is standardly called self, giving us a way to refer to the current object from within its definition. This particular constructor calls the list initializer (similar to calling self = list(children)), then defines the node property of a tree.
|
Next we define another special function that Python knows to call when we index a Tree. The first case is the simplest, when the index is an integer, e.g. t[2], we just ask for the list item in the obvious way. The other cases are for handling slices, like t[1:2], or t[:].
|
This method was for accessing a child node. Similar methods are provided for setting and deleting a child (using __setitem__) and __delitem__).
Two other special member functions are __repr__() and __str__(). The __repr__() function produces a string representation of the object, one that can be executed to re-create the object, and is accessed from the interpreter simply by typing the name of the object and pressing 'enter'. The __str__() function produces a human-readable version of the object; here we call a pretty-printing function we have defined called pp().
|
Next we define some member functions that do other standard operations on trees. First, for accessing the leaves:
|
Next, for computing the height:
|
And finally, for enumerating all the subtrees (optionally filtered):
|
8.2 Processing Classes: N-gram Taggers in NLTK
This section will discuss the tag.ngram module.
8.3 Duck Typing
[to be written]
About this document...
UPDATED FOR NLTK 3.0. This is a chapter from Natural Language Processing with Python, by Steven Bird, Ewan Klein and Edward Loper, Copyright © 2019 the authors. It is distributed with the Natural Language Toolkit [http://nltk.org/], Version 3.0, under the terms of the Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 United States License [http://creativecommons.org/licenses/by-nc-nd/3.0/us/].
This document was built on Wed 4 Sep 2019 11:40:48 ACST